我已经使用 Laravel jobs 和 queues 好几年了。当我刚开始使用它们时,感觉非常困难,我无法理解这些概念,我们构建依赖于它们的 Web 应用程序的方式看起来有点奇怪,如果不说是过于复杂的话。然后有一天,我突然明白了,一切都开始变得清晰起来。希望你也会有同样的感觉,你会开始想知道为什么你这些年来没有使用它们。
据我所知,学习 jobs 和 queues(例如在 Laravel 中)的主要问题不是它本身的复杂性或新颖性,而是我们在线找到的大多数学习资源主要关注理论上的东西,或者给出了一些我们在现实世界中找不到的非常简单的例子。
我写这篇教程是为了我的过去,这是我希望在我第一次学习这些概念时能看到的教程。我喜欢用例子来解释任何复杂的概念。我们将一起构建一个简单的分析应用程序的一部分,我们将从一个非常基础的版本开始,就像你是这个应用程序的唯一用户一样,然后我们将发现这种方法的不足之处,以及 jobs 和 queues 如何帮助我们改进它并解决我们将会面临的一些重大问题。
应用程序说明
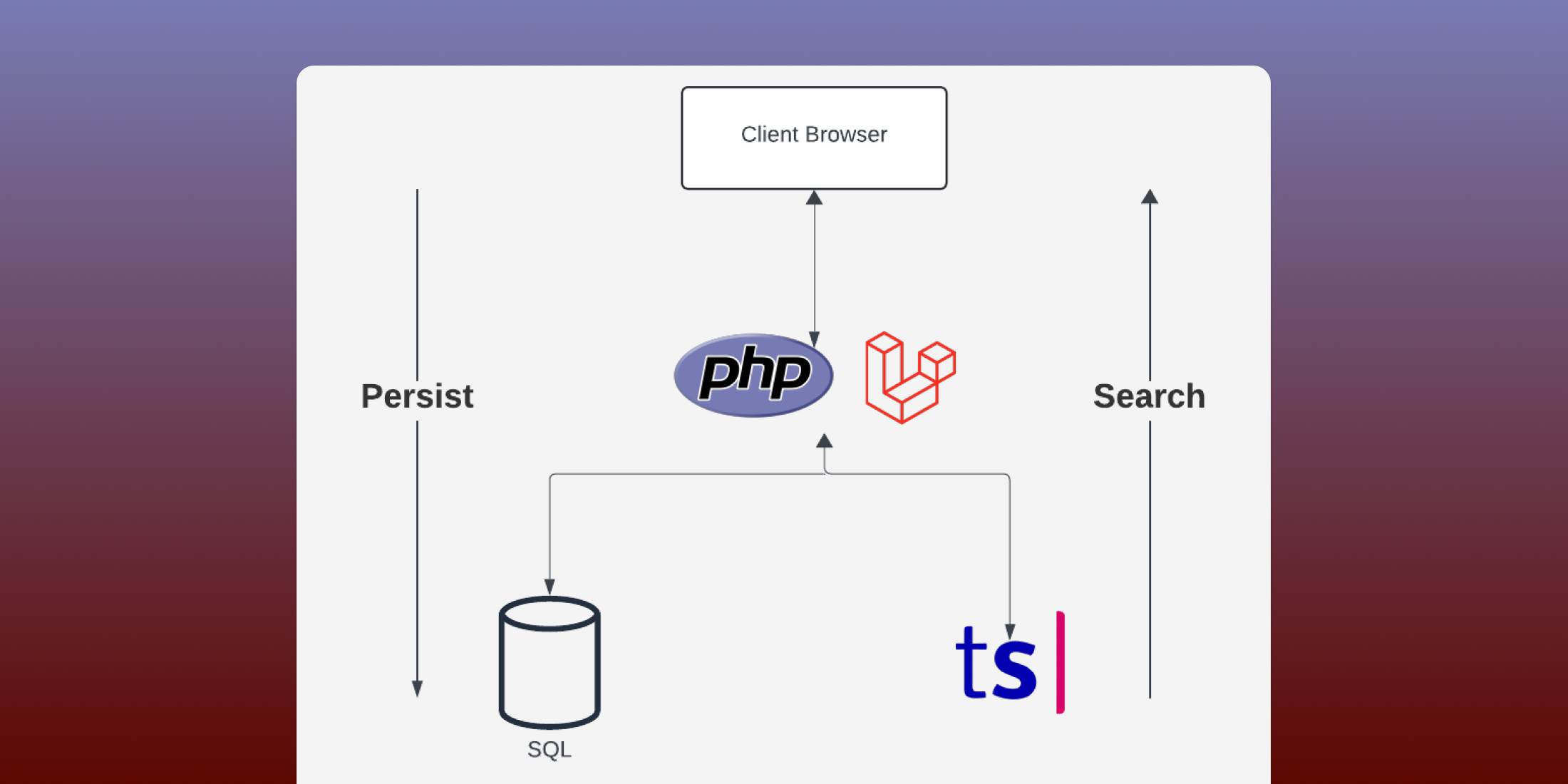
我们的应用程序(我们将其命名为 basic-analytics-v01)非常基础。它是一个应用程序,可以让我们跟踪我们网站的访问量。
让我们构建这个应用程序,同时记住我们可能希望将其开放给其他用户,因此我们需要将用户数据分开,并且不应该需要大量工作才能将其集成到现有网站中。
简而言之,每次用户访问其网站页面时,该网站将向我们分析工具中的特定端点发送一个 POST 请求,然后我们将通过减去两个连续 POST 请求的时间戳来计算在每个页面上花费的时间。
basic-analytics-v01
我们将使这个应用程序(或者至少是它的第一个版本)非常简单。
让我们专注于将这些访问存储到数据库中,我们只需要一个端点和一个控制器(是的,我们现在将所有内容都放在一个控制器中)。
首先,让我们创建两个主要模型及其各自的迁移。
-
Tracker:每个网站将拥有一个唯一的跟踪器,目前,我们只需要确保跟踪器的ID是有效的(存在于数据库中)并且是唯一的。 -
Hit:每个POST请求都将作为“访问”存储。
我们的控制器代码将如下所示
class TrackingController extends Controller{ public function track($tracker_public_id, Request $request){ $tracker = Tracker::where('public_id', $tracker_public_id)->first(); if ($tracker) { $url = $request->get('url'); $hit = Hit::create(['tracker_id' => $tracker->id, 'url' => $url]); $previousHit = Hit::where('tracker_id', $tracker->id)->orderBy('id', 'desc')->skip(1)->first(); if ($previousHit) { $previousHit->seconds = $hit->created_at->diffInSeconds($previousHit->created_at); $previousHit->save(); return $previousHit->seconds; } return 0; } return -1; }}请记住,这里我们简化了很多东西,我们只对有助于说明本文目的的用例感兴趣。
如你所见,这段代码没有问题,特别是如果你要处理的只是一个小型个人网站。
但是,让我们想象一下在哪些情况下这段代码不够好,或者会直接崩溃。
响应时间
让我们假设发送这些请求的脚本需要,出于某种原因,等待并确认请求已收到。
当我使用 Postman 在本地发送请求进行测试时,我得到了以下结果
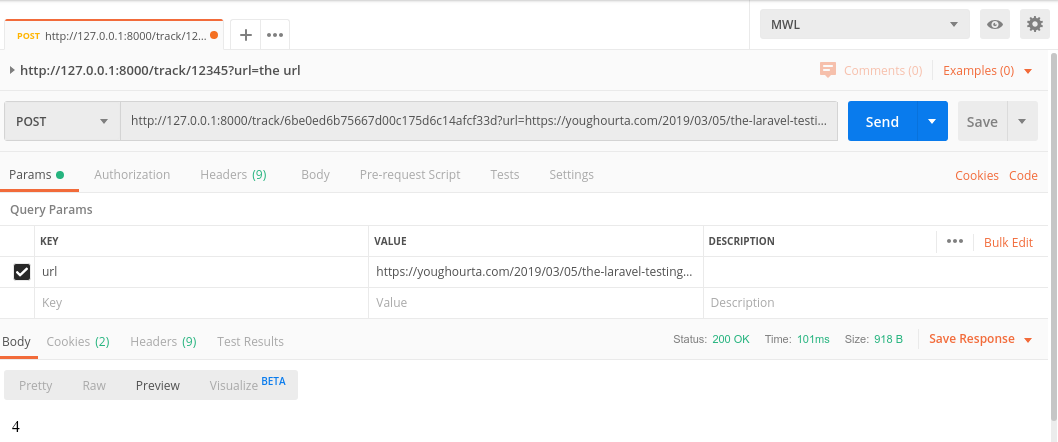
100 毫秒相当长,即使我们在控制器操作中没有进行太多处理。想象一下,我们正在做比这简单的处理更多的事情,我们需要执行多个数据库查询,甚至与第三方 API 交谈,我们将阻塞发送请求的脚本(因此,我们可能会阻塞执行脚本的页面),直到我们完成处理。
并发请求数量
无论你是在本地运行 Laravel 应用程序还是在生产服务器上运行,始终存在你可以同时处理多少个请求的限制。
如果你正在使用本地开发服务器,并使用 php artisan serve 为 Laravel 应用程序提供服务,你会注意到该服务器一次只能处理一个请求。
如果我们像代码中那样同步执行代码,这意味着我们更频繁地达到这个限制,因为我们让 Web 服务器保持忙碌状态,并且我们会注意到太多请求超时。解决此问题的解决方案之一是在尽可能短的时间内释放连接。
数据丢失
阅读当前代码时,一个不容易想到的问题是,如果发生故障(例如,当我们尝试执行代码时无法访问数据库,或者我们有抛出异常的错误),我们无法存储请求并重试。
现在让我们看看 jobs 和 queues 的使用如何帮助我们解决所有这些问题
将 jobs 推送到 queue
首先,让我们谈谈 queue 和 jobs 是什么。
简而言之,job 是我们想要执行的代码片段(例如方法)。我们将它放入 queue 中以延迟其执行,并将它委托给“其他东西”。
举一个现实世界的例子,当你去快餐店吃饭时,接电话的接待员不会是那个为你准备食物并送给你的人,而是确保你的订单被正确接收,然后将剩下的工作“委托”给其他人。
这样做的原因是,接待员不需要让你排队等待直到你拿到订单,而是只做最少和必要的工作,然后继续下一个订单(尽可能多地并行服务其他人)。我们想在代码中实现相同的功能。
因此,在我们的代码中,我们只想确保 POST 请求已收到,然后将剩下的工作委托给应用程序的另一个部分。
一种方法是将我们想要委托的代码放在闭包中,并将其分派到 queue 中,如下所示
dispatch(function () use ($parameters) { // your code here});但我建议你为代码创建一个专门的 job 类,然后将其分派。
首先,我们需要执行以下命令来创建该类
php artisan make:job TrackHitJob此命令将生成以下类
App\Jobs\TrackHitJob现在让我们将代码从TrackingController中的track移动到新创建的TrackHitJob类的handle方法中。handle方法应该如下所示
public function handle(){ $tracker = Tracker::where('public_id', $tracker_public_id)->first(); if ($tracker) { $url = $request->get('url'); $hit = Hit::create(['tracker_id' => $tracker->id, 'url' => $url]); $previousHit = Hit::where('tracker_id', $tracker->id)->orderBy('id', 'desc')->skip(1)->first(); if ($previousHit) { $previousHit->seconds = $hit->created_at->diffInSeconds($previousHit->created_at); $previousHit->save(); return $previousHit->seconds; } return 0; } return -1;}PS:不要忘记导入Tracker和Hit模型以及Request类。
但是我们如何将参数(跟踪器公共 ID 以及请求本身)传递给跟踪代码呢?嗯,我们会将它们传递给类的构造函数,然后handle方法可以像这样获取它们
<br></br>namespace App\Jobs; use Illuminate\Bus\Queueable;use Illuminate\Contracts\Queue\ShouldQueue;use Illuminate\Foundation\Bus\Dispatchable;use Illuminate\Queue\InteractsWithQueue;use Illuminate\Queue\SerializesModels;use Illuminate\Http\Request;use App\Tracker;use App\Hit; class TrackHitJob implements ShouldQueue{ use Dispatchable, InteractsWithQueue, Queueable, SerializesModels; private $trackerPublicID; private $url; public function __construct($tracker_public_id, Request $request) { $this->trackerPublicID = $tracker_public_id; $this->url = $request->get('url'); } public function handle() { $tracker = Tracker::where('public_id', $this->trackerPublicID)->first(); if ($tracker) { $hit = Hit::create(['tracker_id' => $tracker->id, 'url' => $this->url]); $previousHit = Hit::where('tracker_id', $tracker->id)->orderBy('id', 'desc')->skip(1)->first(); if ($previousHit) { $previousHit->seconds = $hit->created_at->diffInSeconds($previousHit->created_at); $previousHit->save(); return $previousHit->seconds; } return 0; } return -1; }}现在,每次我们收到新的点击时,都需要调度一个新的作业。
我们可以按照以下步骤进行操作
namespace App\Http\Controllers; use Illuminate\Http\Request;use App\Jobs\TrackHitJob; class TrackingController extends Controller{ public function track($tracker_public_id, Request $request) { TrackHitJob::dispatch($tracker_public_id, $request); }}看看我们的控制器多么干净简洁。
如果您尝试像我们之前一样发送POST请求,我们会注意到没有变化,我们仍然在hits表中看到点击,并且请求仍然需要大约相同的时间(~100ms),就像上次一样。
那么,这里发生了什么事?我们真的在委托吗?
队列连接
如果您打开.env文件,您会发现我们有一个名为QUEUE_CONNECTION的变量,它被设置为sync。
QUEUE_CONNECTION=sync这意味着,我们正在立即处理所有作业,并且我们正在同步执行此操作。
因此,如果我们想从队列的强大功能中获益,我们需要将这个队列连接更改为其他东西。换句话说,我们需要一个可以“排队”/存储作业的地方,然后再进行处理。
有很多选择。如果您看一下config/queue.php,您会注意到 Laravel 默认支持多种连接(“sync”、“database”、“beanstalkd”、“sqs”、“redis”)。
由于我们才开始使用队列和作业,所以现在让我们先避免任何需要第三方服务(beanstalkd 和 Amazon SQS)或我们开发机器上没有的应用程序(redis)的队列连接。现在,我们将使用database。
因此,每次我们收到一个新的作业,它都会被存储在数据库中(在一个专门的表中)。然后它会被提取并处理。
PS:如果您正在使用本地开发服务器,请不要忘记重新启动它,否则您对.env文件所做的更改不会被考虑。
QUEUE_CONNECTION=database在我们尝试发送POST请求之前,我们需要创建一个表来存储这些作业。幸运的是,Laravel 为我们提供了一个命令,可以为我们生成这个表。
php artisan queue:table执行完这个命令(并创建迁移)后,我们需要运行迁移
php artisan migrate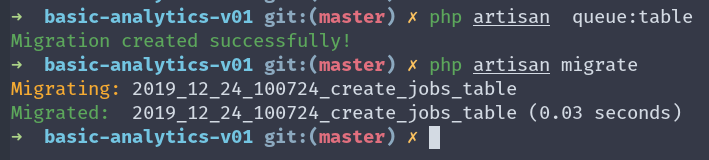
现在,如果我们再次发送POST请求,我们会注意到以下情况
- 响应时间略微降低(因为我们不再同步处理请求)。
- 我们可以在
jobs表中看到一个新条目。
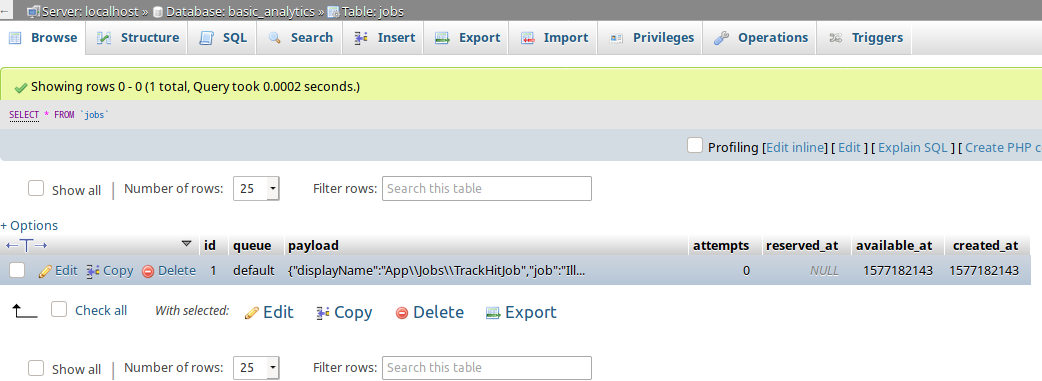
- 但是
hits表中没有新条目。
我们没有在hits表中看到任何条目,因为我们没有任何进程可以“消费”队列中的作业。为了消费它们,我们需要执行以下命令
php artisan queue:work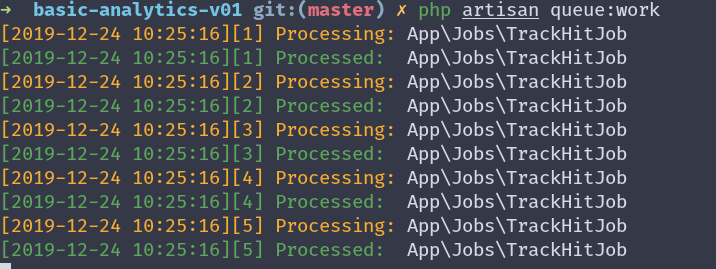
➜ basic-analytics-v01 git:(master) ✗ php artisan queue:work [2019-12-24 10:25:16][1] Processing: App\Jobs\TrackHitJob[2019-12-24 10:25:16][1] Processed: App\Jobs\TrackHitJob[2019-12-24 10:25:16][2] Processing: App\Jobs\TrackHitJob[2019-12-24 10:25:16][2] Processed: App\Jobs\TrackHitJob[2019-12-24 10:25:16][3] Processing: App\Jobs\TrackHitJob[2019-12-24 10:25:16][3] Processed: App\Jobs\TrackHitJob[2019-12-24 10:25:16][4] Processing: App\Jobs\TrackHitJob[2019-12-24 10:25:16][4] Processed: App\Jobs\TrackHitJob[2019-12-24 10:25:16][5] Processing: App\Jobs\TrackHitJob[2019-12-24 10:25:16][5] Processed: App\Jobs\TrackHitJob请注意,此命令不会退出,它会一直等待处理任何新的传入作业。
如果您想知道您如何在生产服务器上执行此命令,以及如何在您退出服务器后保持它运行,请不要担心,我们将在后面深入讨论这一点。
现在,如果您回到数据库中的jobs表,您会发现它是空的,因为所有作业都已处理。
并行消费多个作业
在我们看到如何调度作业并异步处理它们(即:我们不需要等待作业完成)之后,让我们转到我们使用作业和队列的第二个原因:并行。
如果您一直在仔细地关注,您会注意到,即使我们正在调度作业并委托它们,我们仍然一次只处理一个作业。
解决方案非常简单,只需打开一个新的终端选项卡并执行我们之前执行的相同php artisan queue:work命令,下次您向您的应用程序发送多个 POST 请求时(例如,当有多个作业在队列中等待时),您会注意到两个选项卡中的进程都在消费作业,这意味着我们正在并行处理它们,并且您拥有的进程越多,您清空队列的速度就越快。
同样,如果您想知道您如何在生产服务器上执行此操作,请不要担心,我们将在后面详细介绍。
处理失败的作业
现在想象一下,您将一些新代码推送到您的服务器上,这些代码引入了错误,并且您花费了一些时间才发现它,这意味着您的应用程序在此期间收到的所有请求都会失败,有没有办法在修复错误后处理它们。正如您所知,您不能让您的客户再次向您发送请求(这根本不可能)。幸运的是,数据并没有丢失,我们可以毫无问题地重试失败的作业。
但是在我们探索如何做到这一点之前,我建议您阅读queue:work命令的帮助信息
php artisan queue:work --help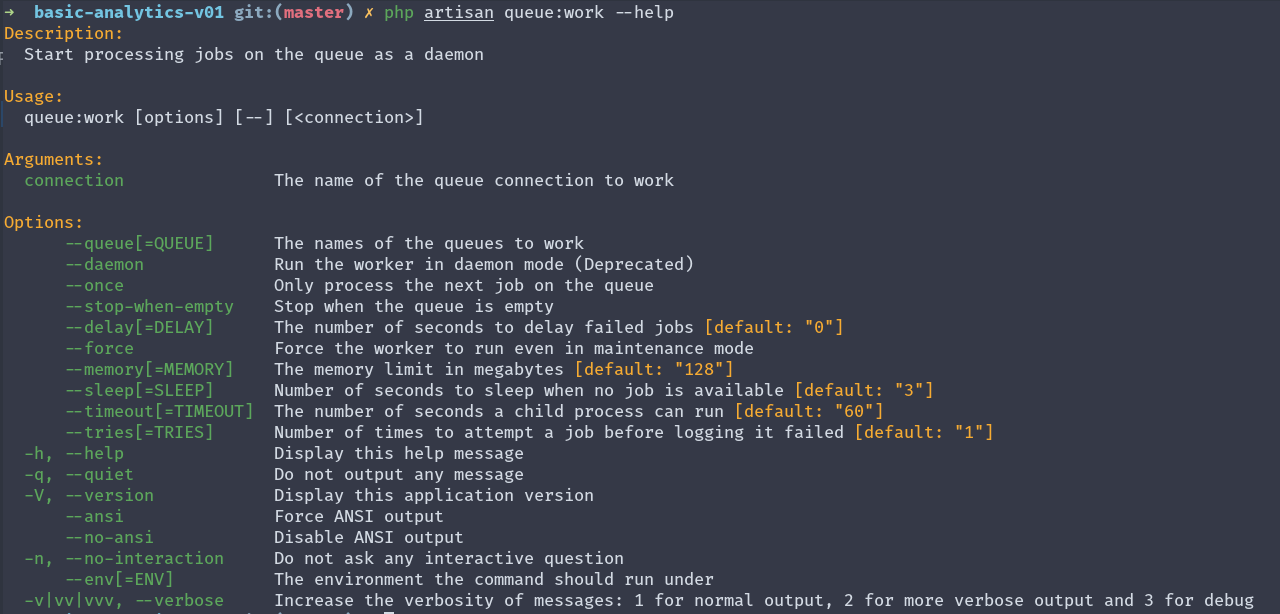
请注意,该命令接受多个参数,其中一个(这里我们感兴趣的那个)是tries参数
--tries[=TRIES] Number of times to attempt a job before logging it failed [default: "1"]此参数可以帮助我们确定在将作业标记为失败之前重试该作业多少次。请注意,默认值为1,这意味着只要作业失败一次,它就会被标记为失败。
当作业失败时,它将被持久化到failed_jobs表中,Laravel 为我们提供了一个命令,可以创建这个表的迁移
php artisan queue:failed-table换句话说,如果您在您的应用程序中使用作业和队列,您需要运行此命令以及由此产生的迁移。
现在,让我们停止所有queue:work进程,并尝试模拟一个失败的作业。
让我们在handle()方法的开头添加以下行
throw new \Exception("Error Processing the job", 1);因此,每次我们尝试处理作业时,作业都会失败,看看会发生什么(不要忘记发送一些新的 POST 请求)

如您所见,作业正在失败,如果我们访问failed_jobs表,我们可以找到有关它们的更多信息。
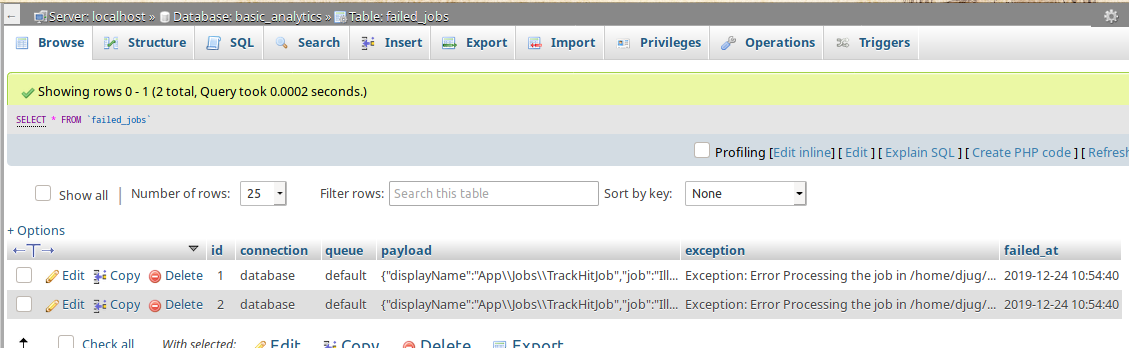
对于每个条目,我们可以看到作业的有效负载、导致它失败的异常以及连接、队列和作业失败的时间。
现在,让我们删除抛出异常的那一行,让我们再次重试这些作业。
我们可以像这样重试所有失败的作业或仅重试一个特定的作业(将all替换为作业的 ID)
php artisan queue:retry all如果您在重试作业之前没有停止之前的queue:work进程,您会注意到重试的作业再次失败。那么,这里发生了什么事?
根据 Laravel 文档
队列工作者是长期运行的进程,它们将启动的应用程序状态存储在内存中。因此,在它们启动后,它们不会注意到代码库中的任何更改。因此,在您的部署过程中,请确保重新启动您的队列工作者.
因此,我们需要再次重新启动该进程。
或者,如果您想避免每次在本地更改某些内容时都重新启动进程,您可以改用以下命令
php artisan queue:listen但是,根据官方文档,此命令不像queue:work:那样高效
现在,让我们再次重新启动queue:work进程,并重试所有失败的作业。
作业将被处理,您将在 hits 表中看到新的条目。
下一步
在下一教程中,我们将了解如何使用其他队列连接(除了数据库连接),我们将探索多个队列的使用方式以及如何让一些作业/队列比其他队列具有更高的优先级。
接下来我们将探索如何部署依赖于作业和队列的应用程序,以及需要做什么来保持进程运行。

后端开发人员 http://youghourta.com 我构建了
- botmarker.com
- bookmarkingBot.com
- todocol.com
我也是“Laravel Testing 101”的作者 http://laraveltesting101.com