处理庞大的 CSV 文件在商业世界中很常见,特别是在你拥有大量数据需要分析、报告或移动时。如果你使用 Laravel 并且需要处理大型 CSV 文件,你已经来对地方了。我们将指导你以最平滑的方式处理此任务,而不会影响应用程序的性能。
内存和性能
首先,让我们谈谈最棘手的问题:内存和性能。处理一个巨大的 CSV 文件会占用大量内存,并可能降低应用程序的速度。当然,你可能会考虑直接增加内存限制或延长超时时间。但说实话,这就像在漏水管上贴创可贴——并非最佳解决方案。
使用 Spatie 的 Simple Excel
与其用创可贴式的解决方案,我们不如使用一个巧妙的包,叫做 Simple Excel,由 Spatie 开发。如果你点头示意,因为你期望 Spatie 有解决方案,那你并不孤单。
composer require spatie/simple-excel假设你已经准备好 CSV 文件,我们将使用 SimpleExcelReader 加载它。最棒的是,默认情况下,它返回一个 LazyCollection——可以将其视为一种更周到的方式来处理数据,而不会耗尽服务器的内存。这意味着你可以逐段处理文件,让应用程序保持轻便。
$rows 是 Illuminate\Support\LazyCollection 的实例
Laravel 任务前来救援
现在,在我们深入代码之前,让我们设置一个 Laravel 任务来管理我们的 CSV 处理过程。
php artisan make:job ImportCsv现在,我们的 ImportCsv 任务看起来像这样
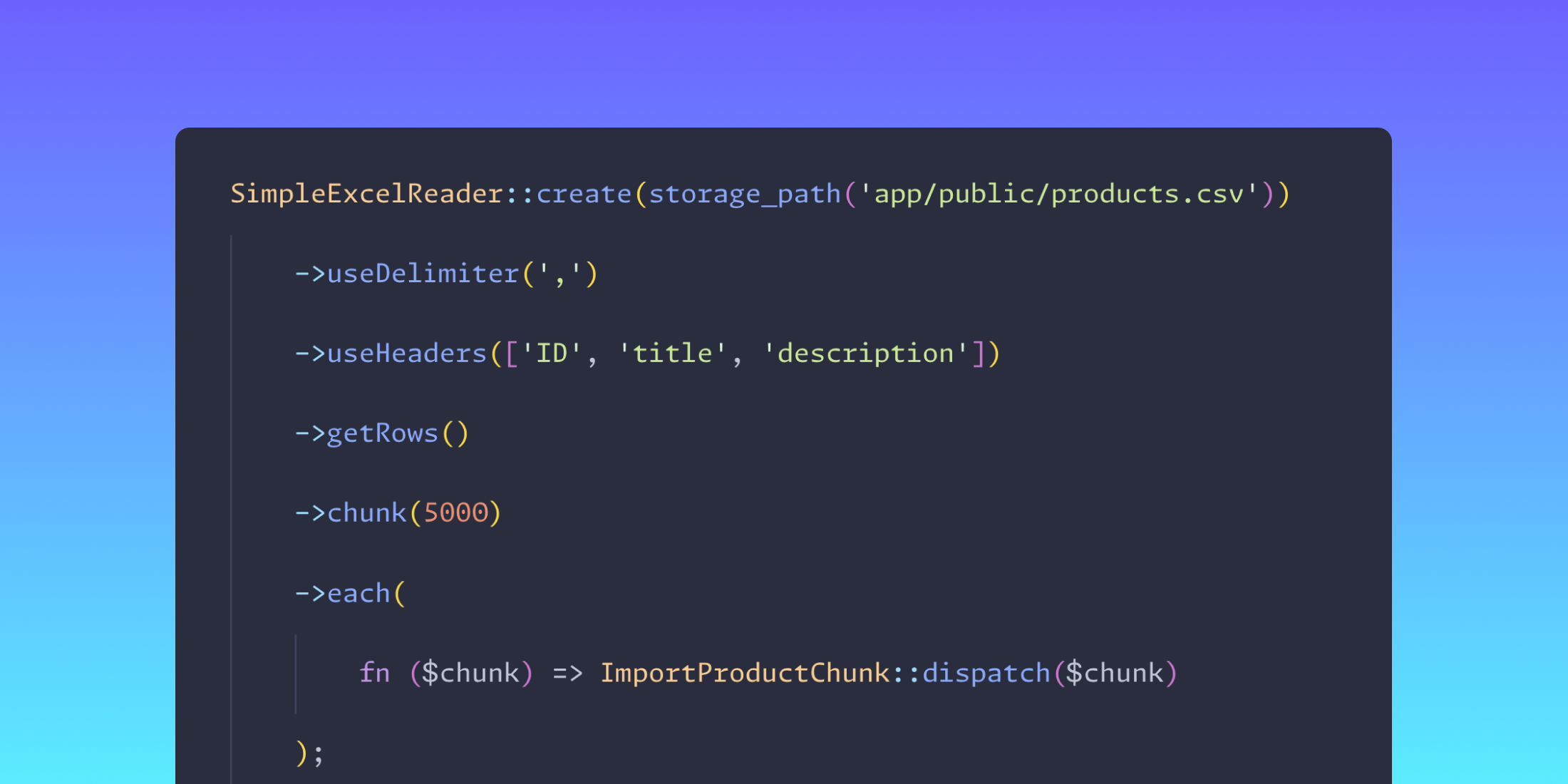
<?php namespace App\Jobs; use Illuminate\Bus\Queueable;use Illuminate\Contracts\Queue\ShouldQueue;use Illuminate\Foundation\Bus\Dispatchable;use Illuminate\Queue\InteractsWithQueue;use Illuminate\Queue\SerializesModels;use Spatie\SimpleExcel\SimpleExcelReader; class ImportCsv implements ShouldQueue{ use Dispatchable, InteractsWithQueue, Queueable, SerializesModels; /** * Create a new job instance. */ public function __construct() { // } /** * Execute the job. */ public function handle(): void { SimpleExcelReader::create(storage_path('app/public/products.csv')) ->useDelimiter(',') ->useHeaders(['ID', 'title', 'description']) ->getRows() ->chunk(5000) ->each( // Here we have a chunk of 5000 products ); }}这是我们的计划
-
**对 CSV 进行分块**:我们将把文件分解成可管理的小块,从而获得一个可以操作的
LazyCollection。 - **任务调度**:对于每个块,我们将发送一个任务。这样,我们就可以分批处理,这对你的服务器来说更加轻松。
- **数据库插入**:每个块随后将被插入数据库,非常轻松便捷。
对 CSV 进行分块
有了 LazyCollection,我们将把 CSV 分割成块。可以将其想象成把一个巨大的三明治切成一口大小的块——更容易处理。
php artisan make:job ImportProductChunk对于 CSV 的每块,我们将创建并触发一个任务。这些任务就像勤劳的工人,每个任务都负责一块,并小心地将数据插入数据库。
<?php namespace App\Jobs; use App\Models\Product;use Illuminate\Bus\Queueable;use Illuminate\Contracts\Queue\ShouldBeUnique;use Illuminate\Contracts\Queue\ShouldQueue;use Illuminate\Database\Eloquent\Model;use Illuminate\Foundation\Bus\Dispatchable;use Illuminate\Queue\InteractsWithQueue;use Illuminate\Queue\SerializesModels;use Illuminate\Support\Str; class ImportProductChunk implements ShouldBeUnique, ShouldQueue{ use Dispatchable, InteractsWithQueue, Queueable, SerializesModels; public $uniqueFor = 3600; /** * Create a new job instance. */ public function __construct( public $chunk ) { // } /** * Execute the job. */ public function handle(): void { $this->chunk->each(function (array $row) { Model::withoutTimestamps(fn () => Product::updateOrCreate([ 'product_id' => $row['ID'], 'title' => $row['title'], 'description' => $row['description'], ])); }); } public function uniqueId(): string { return Str::uuid()->toString(); }}确保唯一性
要记住的一件关键的事情是在你的任务中使用 $uniqueFor 和 uniqueId。这就像给每个工人发放一个独一无二的 ID 徽章,这样你就不会出现两个人做同一份工作的情况——这对效率来说是绝对不可取的。
调度任务
回到我们的 ImportCsv 任务中,我们将在 each 方法中为每个块调度一个任务。这就像在说,“你得到一块,你也得到一块——每个人都得到一块!”
<?php namespace App\Jobs; use Illuminate\Bus\Queueable;use Illuminate\Contracts\Queue\ShouldQueue;use Illuminate\Foundation\Bus\Dispatchable;use Illuminate\Queue\InteractsWithQueue;use Illuminate\Queue\SerializesModels;use Spatie\SimpleExcel\SimpleExcelReader; class ImportCsv implements ShouldQueue{ use Dispatchable, InteractsWithQueue, Queueable, SerializesModels; /** * Create a new job instance. */ public function __construct() { // } /** * Execute the job. */ public function handle(): void { SimpleExcelReader::create(storage_path('app/public/products.csv')) ->useDelimiter(',') ->useHeaders(['ID', 'title', 'description']) ->getRows() ->chunk(5000) ->each( fn ($chunk) => ImportProductChunk::dispatch($chunk) ); }}就这样!你的块将被独立处理,而不会出现任何内存问题。如果你急于完成,只需添加更多工人,就像一台运转良好的机器一样,你的数据将被更快地处理。
在 Laravel 中处理大型 CSV 文件并不需要头疼。只要使用正确的工具和方法,你就可以让应用程序保持平稳运行,同时处理所有数据。
编码愉快!